RAG on a Budget: How I Replaced a $360/Month OpenSearch Cluster with S3 and In-Memory Search
Topics
- AI
- AI Infrastructure
- Amazon Bedrock
- Amazon DynamoDB
- Amazon S3
- Amazon Web Services (AWS)
- API Development
- API Gateway
- AWS
- AWS Cost Optimization
- AWS Lambda
- Back-end Web Development
- Claude
- Front-end Development
- Full-stack Web Development
- Generative AI
- LLMs
- Next.js
- Node.js
- OpenAI
- OpenSearch
- RAG
- React
- RESTful APIs
- Retrieval-Augmented Generation
- System Design
- Technology
- TypeScript
There's a version of this post where I start with the cost savings and you click away satisfied. But the more interesting story is the series of architectural decisions — some deliberate, some forced — that got me from "let's build this properly" to a production RAG system running for about $1 a month.
This is that story.
In January 2026 I did a full rebuild of my professional presence — new Next.js 16 + React 19 portfolio, redesigned from scratch, plus a separate site for my artwork (previously both lived in one codebase). Once those were live, the missing piece was obvious: the AI agent I'd shelved in March 2025 needed to come back, this time production-ready and cost-viable. The rebuilt sites gave it a home worth shipping into.
The Original Goal: Build It Enterprise-Grade
When I decided to add an AI knowledge agent to my personal site, I didn't want a toy. I wanted to understand how production RAG systems actually work — the kind you'd build at a company with real scale requirements. That meant:
A proper vector database (OpenSearch)
External embedding and generation via OpenAI
Clean separation between ingestion, retrieval, and generation
The architecture was sound. The problem was the bill.
OpenSearch's minimum viable cluster runs $360–720/month. For a personal project with a few hundred queries a day, that's unjustifiable. After less than a week of watching that cost accumulate, the question shifted from how do I build this to how do I keep this running without OpenSearch?
What the System Actually Does
Before getting into the migration, here's what I built and why it's worth the effort.
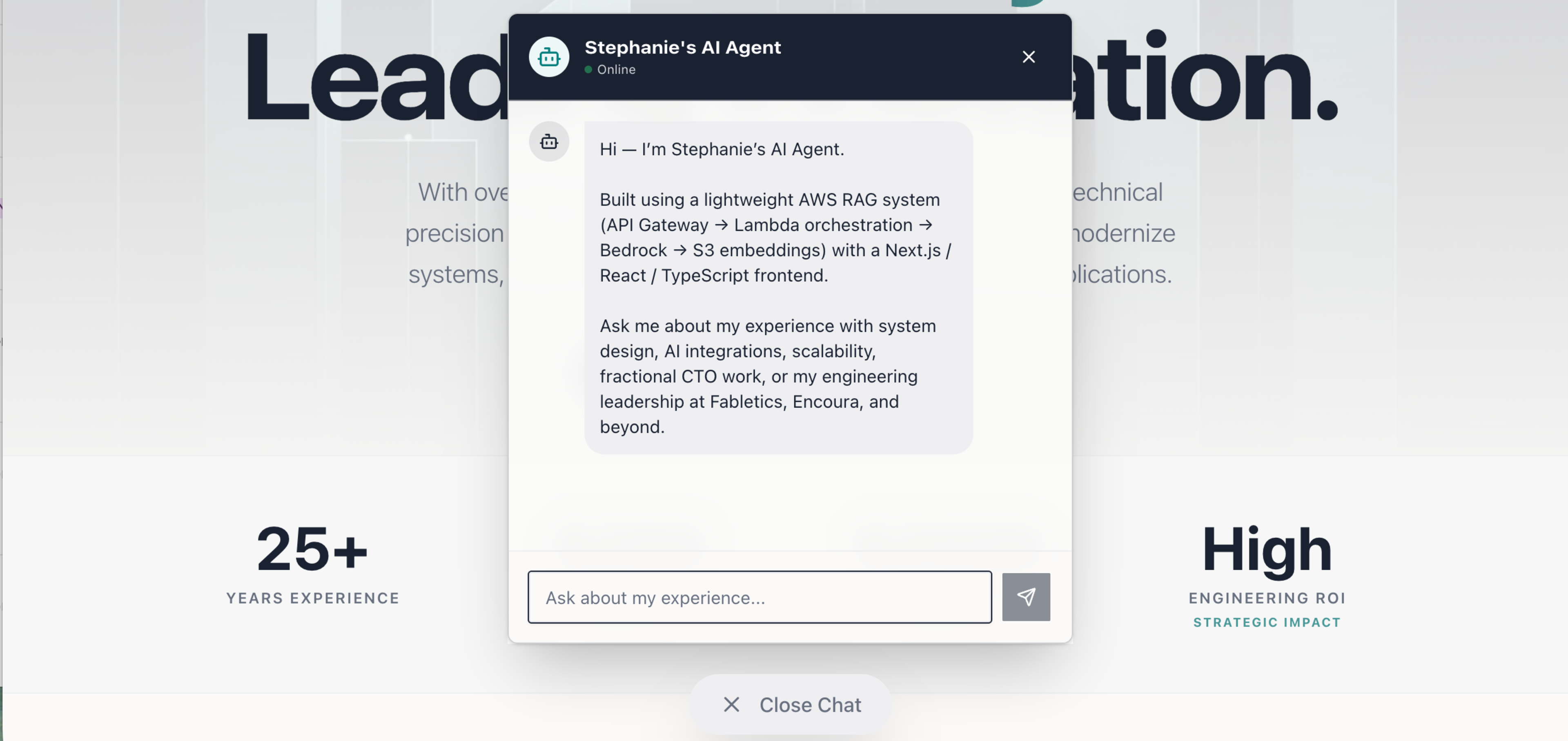
The agent lives on my website and answers questions about my work, experience, and technical background — things a resume can't do. Instead of serving static pages, visitors can ask things like "What's your experience with system design at scale?" or "Have you worked with event-driven architectures?" and get grounded, specific answers drawn from my actual content.
The key word is grounded. This isn't a general LLM answering from training data. Every response is anchored to a curated knowledge base I built and maintain myself — covering 25+ years of engineering experience, employment history, certifications, FAQs, and consulting background.
The API response contract is intentionally simple and observable:
interface ChatResponse {
success: boolean
message: string
error?: string
rateLimited?: boolean
tokensUsed?: number
modelUsed?: string
}
modelUsed is there for a reason — knowing which tier handled a query matters for debugging and understanding cost tradeoffs in production.
The RAG Pipeline
The core flow hasn't changed between architecture versions:
User query
→ Embed the query (vector representation)
→ Cosine similarity search against pre-computed knowledge embeddings
→ Inject top-k results as context
→ Generate response from LLM with that context
→ Return answer + source metadata
What changed is every infrastructure component underneath it.
Version 1: OpenAI + OpenSearch (March 2025)
The first version was architecturally clean but expensive.
Embeddings: OpenAI text-embedding-ada-002
Vector storage: AWS OpenSearch 2.17
Generation: OpenAI GPT-4
Auth: Secrets Manager for API keys
Orchestration: AWS Lambda via AppSync
For embeddings I used OpenAI's text-embedding-ada-002 — the standard choice at the time, producing 1536-dimension vectors. It worked well. The issue wasn't quality; it was that every embedding generation call left AWS, added latency, and accumulated cost alongside the OpenSearch bill. When you're already paying $360/month for the vector database, adding per-token embedding costs and an external network dependency starts to feel like the wrong architecture for the wrong scale.
I built the OpenSearch cluster lean and deliberately minimal — a single t3.small.search node, 1-AZ without standby, 10 GiB EBS gp2 storage, VPC-only access, fine-grained access control, node-to-node encryption, and hourly snapshots. No dedicated master nodes, no UltraWarm, no redundancy I didn't need. This was the smallest viable production configuration.
It still wasn't cheap enough. OpenSearch 2.17 on even a single t3.small.search runs around $360/month just to exist. The cluster was healthy — green status, no issues — but after less than a week of running it I shut it down. The architecture was right. The cost profile wasn't.
That was March 2025. The project sat on the back burner until January 2026, when I came back to it with a different question: what if I didn't need a vector database at all?
Version 2: Amazon Bedrock + S3 + In-Memory Search (January–February 2026)
The migration had one hard constraint: I couldn't just swap the LLM provider. I had to eliminate the vector database entirely or find something that costs effectively nothing at my scale.
The insight was simple: I have fewer than 200 document chunks. That fits comfortably in Lambda's memory. If I precompute all the embeddings, serialize them to S3, and load them at Lambda startup — I don't need a vector database at all.
Everything runs in us-east-1. That's a deliberate choice — the widest model selection and best Amazon Bedrock pricing are there, and keeping Lambda, S3, DynamoDB, and API Gateway in the same region avoids cross-region latency and data transfer costs.
Embedding Storage: S3 as a Dumb Object Store
Every document chunk gets embedded using Amazon Bedrock's Titan Text Embeddings V2. The results are serialized to a single JSON file and written to S3.
The actual bucket is stephanie-knowledgebase-embeddings, created February 1, 2026. It holds three objects: embeddings.json (2.3 MB, prod), embeddings-dev.json (2.3 MB, dev), and a lambda/ folder. Both embedding files were last regenerated February 19, 2026 after a knowledge base update. Total storage cost: ~$0.01/month.
Retrieval: In-Memory Cosine Similarity
On Lambda cold start, the handler fetches the embeddings file from S3 and loads it into memory. It also writes it to /tmp so subsequent warm invocations skip the S3 fetch entirely.
For each query:
Embed the query text with Titan V2
Compute cosine similarity against every stored embedding in memory
Return the top-k results as context
The implementation lives in embeddingStore.ts. For each stored document embedding b and query embedding a, it computes:
dot product: Σ(a_i * b_i)
magnitude of each: sqrt(Σ(a_i²)), sqrt(Σ(b_i²))
cosine similarity: dot / (|a| * |b|)
similaritySearch() runs this against every document, sorts descending, and returns the top-k chunks — which become the context injected into the LLM prompt. Higher cosine score = more semantically similar chunk = more relevant RAG context.
There's no index. No vector database. Just a dot product loop over a few hundred float arrays. At this scale, it's faster than a network call to an external database would be.
Cold start: 3–5 seconds (S3 fetch + embedding load)
Warm invocations: < 500ms total
This is the core architectural bet: the scale doesn't justify the infrastructure. At 200 chunks, in-memory search is not a compromise — it's the right tool.
Generation: Tiered Model Routing — and a Production Reality Check
The design called for three Amazon Bedrock models at three cost tiers:
Tier | Model | Daily Limit | Cost / Query |
1 | Claude 3.5 Sonnet | 1 | $0.009 |
2 | Claude 3.5 Haiku | 10 | $0.001 |
3 | Llama 3.3 70B | Unlimited | $0.0008 |
In practice, Anthropic models on Amazon Bedrock have been consistently unreliable for me. AWS Marketplace agreements for Anthropic models keep expiring immediately after acceptance — I'd get the "offer accepted" email followed minutes later by "agreement expired." I've filled out the required use-case forms, but something in the approval flow keeps breaking. I can call the Anthropic API directly with my own keys without any issues, but I specifically wanted to keep the model abstracted behind Amazon Bedrock so the provider wasn't baked into the application layer.
The result: in production, the system always routes to Llama 3.3 70B, which turns out to work just fine. The tiered routing logic is fully in place — ready to use Claude the moment Amazon Bedrock access resolves — but for now Llama handles all queries, and the quality is solid.
This is the part of production systems that doesn't show up in architecture diagrams: sometimes a dependency you designed around simply doesn't work, and you ship with what does.
Rate Limiting: DynamoDB as a Budget Enforcement Layer
The rate limiter tracks usage at three granularities:
Per-session
: 5 queries max (prevents abuse)
Per-day
: 50 queries total
Per-month
: 1,000 queries total
The bedrock-rate-limits table uses userId (String) as the partition key and timestamp (Number) as the sort key, on-demand capacity mode. As of today it holds 49 items at 6.1 KB total — real usage, not a test table. Records expire automatically with a 90-day TTL. Cost: $0 (DynamoDB free tier).
API Layer: API Gateway + Lambda with Key Auth
Two Lambda functions — KnowledgeableAgent (prod) and KnowledgeableAgentDev — both Node.js 20.x, deployed as Zip packages, triggered by their respective API Gateway REST APIs. The prod API was created February 2, 2026; dev came online February 20 after I formalized the environment separation. Both are regional, TLS 1.0, API key authenticated, and status Available.
The full request path:
Next.js 16 frontend
→ POST /chat (API Gateway)
→ x-api-key header validation
→ Lambda handler (Node.js 20.x)
→ Rate limit check (DynamoDB bedrock-rate-limits)
→ Query embedding (Amazon Bedrock Titan V2)
→ Similarity search (in-memory, embeddings.json from S3)
→ Context injection
→ LLM generation (Llama 3.3 70B via Amazon Bedrock)
→ ChatResponse with answer + sources + modelUsed + tokensUsed
A note on the API key auth: yes, an API key is a lightweight security mechanism — not OAuth, not JWT, not Cognito. That's a deliberate tradeoff, not an oversight. Two things make it appropriate here. First, ALLOWED_ORIGINS is configured to restrict requests to my own domains, so even if someone had the key, cross-origin calls from arbitrary clients get rejected. Second, the calls are made server-side from the Next.js backend — the key is never exposed to the browser. Combined with rate limiting already enforced at the DynamoDB layer, this is a reasonable security posture for a personal site. If this were handling sensitive user data or financial transactions, the answer would be different.
Building the Knowledge Base: An Editorial Workflow, Not Just JSON Files
The starting point was everything I already had: website pages, blog posts, resume, Contra and Upwork profiles. The raw material existed — it just lived in too many places with too much overlap. The about page, homepage summary, and resume introduction all said essentially the same things in slightly different words. The case studies section of the site duplicated content that already lived in blog posts.
My workflow:
AI-assisted summarization — I worked with various AI editors to distill each source into well-structured chunks. This got the content into roughly the right shape quickly.
Manual proofread for accuracy — Every chunk was read and verified against the source. AI summaries compress things; sometimes they compress the wrong things.
Deduplication with Claude Code — Ran Claude Code across the knowledge base to identify redundancies. Overlapping content from the about page, homepage, and resume was consolidated into
about-page.jsonas the single source of truth. The case studies section was excluded entirely — that content is already in the blog posts, and indexing it twice would pollute retrieval with duplicates.Structural decisions — Each JSON file maps to a domain: employment history, certifications, FAQs, consulting services, about. Each
content_chunkhas its ownid,title, andchunktext, with an emptyembeddingarray that gets populated at generation time.
Here's what a real chunk from certifications.json looks like:
{
"id": "cert-001",
"title": "Education: UC Berkeley",
"chunk": "Education: Bachelor of Science in Physics & Astronomy, UC Berkeley, December 1999.",
"embedding": []
}
And from techstyle.json — a chunk that captures a specific, measurable outcome:
{
"id": "techstyle-001-2",
"title": "Variant Price Testing Project",
"chunk": "Designed and implemented an A/B testing strategy for dynamic price testing, leading to a $250,000 increase in revenue within the first three days. Architected and developed two high-performance TypeScript API microservices deployed in Mesosphere DC/OS.",
"embedding": []
}
The chunk granularity matters. Too broad and cosine similarity can't differentiate relevance. Too narrow and you lose context. The employment history files use a challenge/solution/result pattern for each project — that structure makes retrieval more precise for questions about specific work.
The tradeoff is real: manual curation doesn't scale. When the Contentful ingestion pipeline is validated and the chunking strategy is proven, I'll switch to automated ingestion. Until then, I know exactly what the agent knows and how it says it.
Dev/Prod Separation
Separate environments from day one.
DEPLOY_ENV=dev ./deploy-lambda.sh
Dev uses embeddings-dev.json and a separate API key via KnowledgeableAgentAPIDev. I can push knowledge base changes, test retrieval quality in the actual chat UI, and validate rate-limit behavior without touching the production assistant. Only after validating in dev does anything get promoted to prod.
For a solo project, this discipline pays off quickly — a bad embeddings file or a broken prompt template is annoying in dev and embarrassing in prod.
Cost Comparison
Component | Before | After |
Vector DB | $360–720/mo | $0.01/mo |
LLM + Embeddings | $5–10/mo | $1.11/mo |
Infrastructure | ~$10/mo | $0/mo |
Total | $365–730/mo | ~$1.12/mo |
The 99.7% reduction isn't primarily about being clever with LLM costs. It's about eliminating the always-on vector database that was charging rent regardless of traffic.
What This Architecture Can't Do
Doesn't scale past ~10K chunks. In-memory cosine similarity works at this scale. Above 10K chunks, you need a proper index — Pinecone's free tier or OpenSearch Serverless are the right next step.
Cold starts are real. The first query after a period of inactivity takes 3–5 seconds while Lambda fetches embeddings from S3. Acceptable for a personal site; not acceptable for a latency-sensitive product.
No real-time knowledge updates. Adding content requires regenerating embeddings and redeploying. For a knowledge base that changes infrequently, this is fine.
External provider dependencies bite. The Anthropic/Amazon Bedrock access issue is a live example. Even with fallback logic designed in, a dependency that's supposed to work might not.
Does It Actually Work?
The first real test was a Postman request — "Tell me about your experience with team management" — hammered repeatedly until the retrieval and response quality felt right. That particular query is a good stress test because team management context is distributed across multiple files: employment history chunks, the about page leadership section, FAQ entries. Getting a coherent, grounded answer required the similarity search to pull the right combination of chunks and the LLM to synthesize them cleanly. When it started coming back with specific, accurate answers instead of generic ones, that was the signal.
More interesting than the questions it answers well are the edges. I deliberately tested queries the agent shouldn't be able to answer — things outside the knowledge base entirely — and it correctly declined rather than hallucinating. But the most revealing test was asking "Are you kind?"
There's no chunk in the knowledge base that answers that directly. Instead, the agent pulled from the core values section of the about page and cross-referenced tone from blog writing to construct a thoughtful response. It wasn't a stored answer — it was synthesis. Seeing it work on a soft, subjective question was more convincing than any technical benchmark.
What's Next
The immediate roadmap is intentionally minimal. The Contentful ingestion pipeline exists but isn't production-ready — it will get validated when there's enough new content to justify switching from manual curation. Resolving the Anthropic/Amazon Bedrock access issue remains open. And this blog post itself is the next piece of content going into the knowledge base once it's published — which feels like an appropriate closing of the loop.
What This Demonstrates
Beyond the cost numbers, this project is an exercise in matching infrastructure to actual scale requirements — a thing that's easy to get wrong when you're learning a new domain and want to do it "properly."
OpenSearch is the right tool for a team running millions of vector queries against a corpus of millions of documents. It's the wrong tool for a personal site with 200 chunks and a few dozen queries per day. Recognizing that distinction, and being willing to trade architectural prestige for operational reality, is its own kind of engineering judgment.
The tiered model routing, DynamoDB-based rate governance, API key authentication, dev/prod separation, and deliberate knowledge base curation aren't over-engineered additions — they're the parts that make this viable as a real, running system rather than a demo that works once and gets shut down.
Stack Summary
Frontend: Next.js 16 + React 19 + TypeScript
API: AWS API Gateway (REST, regional, API Key auth, TLS 1.0)
Compute: AWS Lambda (Node.js 20.x, Zip deployment)
Embeddings: Amazon Bedrock Titan Text Embeddings V2
Vector storage: S3
stephanie-knowledgebase-embeddings(2.3 MB JSON) + in-memory cosine similarityGeneration: Llama 3.3 70B via Amazon Bedrock (Claude 3.5 Sonnet/Haiku in routing logic, pending Amazon Bedrock access resolution)
Rate limiting: DynamoDB
bedrock-rate-limits(on-demand,userId+timestampkeys, 90-day TTL)Region:
us-east-1throughoutInfrastructure: IAM, CloudWatch, TypeScript build pipeline
Knowledge base: Handcrafted JSON with AI-assisted summarization, manually proofread and deduplicated via Claude Code
The full migration guide and deployment scripts are in the repo if you want to adapt this for your own use case.